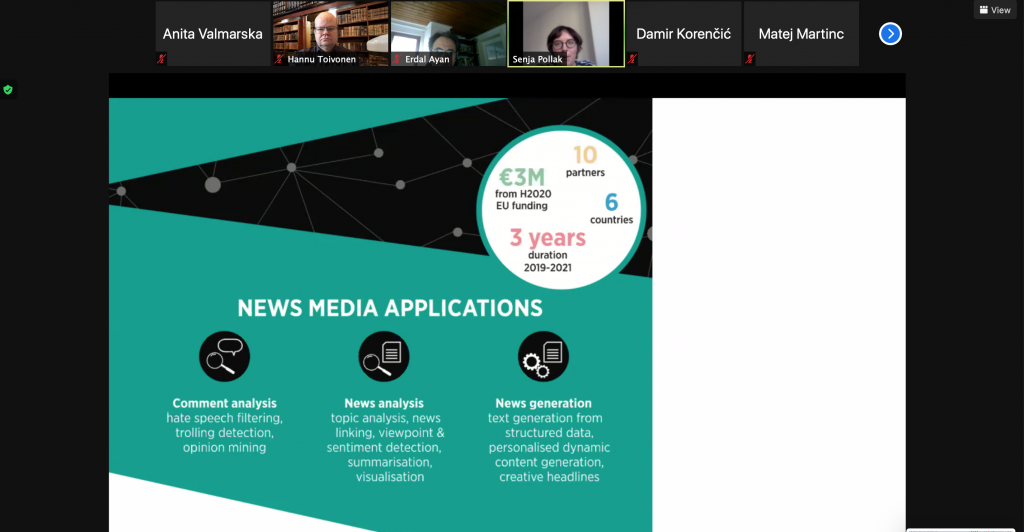
On April 19, we wrapped the EACL Hackashop on News Media Content Analysis and Automated Report Generation. The aim of Hackashop 2021 was to foster discussion and research on the combination of language technology and news media content. It provided a forum for both discussing scientific advances in the analysis of news stories and their reader comments and automated generation of reports, as well as for experimental work on identifying interesting phenomena in reader comments and reporting on them.
The hackashop was implemented in a dual format. A traditional track consisted of submission of scientific papers, their reviews, and finally paper presentations. It was complemented by an active, experimentation-based track consisting of an online hackathon preceding the workshop, with the presentation of the results in the joint workshop event. Both tracks shared the same topic, news media analysis, and generation, and participants to the two tracks had a good amount of overlap.
In the workshop track, we encouraged submissions of long and short papers. Based on three expert reviews for each submission, weighing the contributions of the submission against its length, 13 papers were selected for presentation in the workshop event.
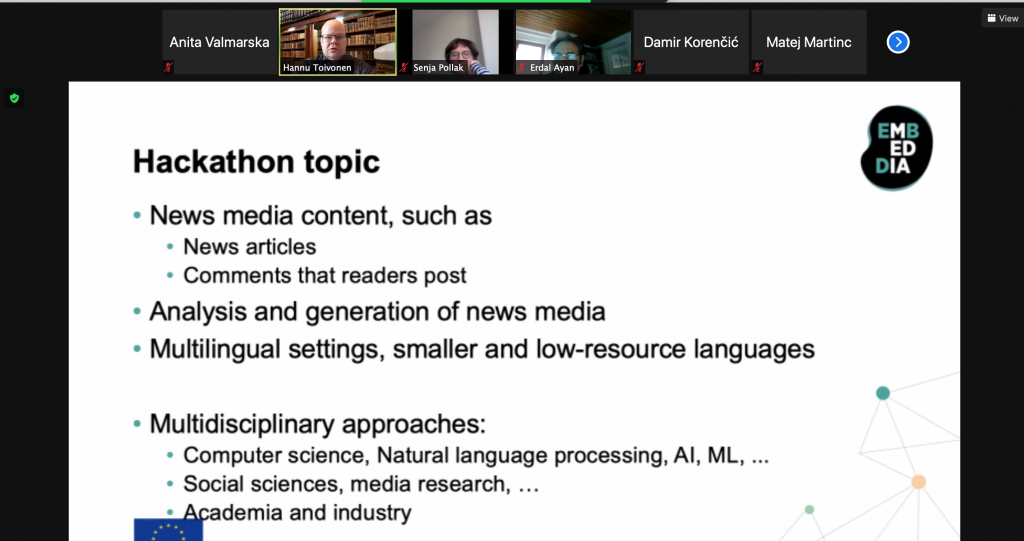
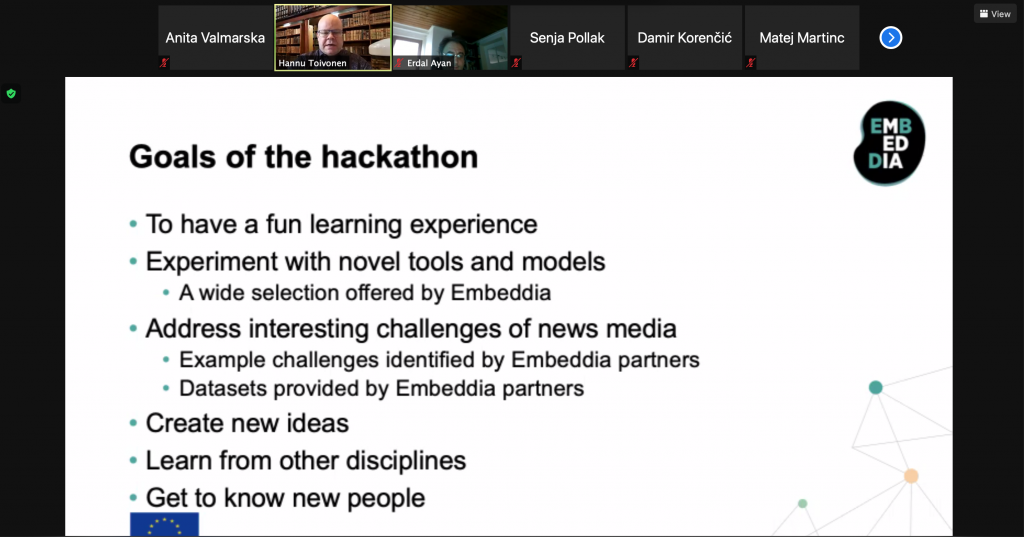
The online hackathon was organized during a three-week period in February 2021, with six participating teams. The challenges they addressed covered a broad range, as each team had the freedom to define their own aims. In the spirit of providing a joint forum for discussing both scientific advances and experimental work, five hackathon teams submitted short reports to be included in this proceedings.
We were very happy to see several cross-disciplinary and cross-sector collaborations involving, e.g., computer scientists, social scientists, and the media industry, both in workshop papers and hackathon contributions. We were also happy to have numerous contributions that address multilingual settings and low-resource languages.
The workshop event on 19 April 2021 brought both tracks together, with presentations of both scientific workshop papers and empirical hackathon reports. We concluded the Hackashop with an excellent presentation of our keynote speaker, professor Neil Maiden.
We would once again like to thank all workshop paper authors and hackathon participants for their contributions to the hackashop! We are thankful to the programme committee members for their insightful reviews of the workshop papers. We are equally thankful to the large number of experts who made tools, models, data, and challenges available for the hackathon and provided support for the participants.
Authors: Hannu Toivonen and Michele Boggia