We are pleased to present 6 EMBEDDIA publications accepted at this year’s Language Resources & Evaluation Conference (LREC 2020). Details of the submitted papers are presented below (will be updated with final versions in the beginning of May).
Leveraging Contextual Embeddings for Detecting Diachronic Semantic Shift by Matej Martinc, Petra Kralj-Novak, and Senja Pollak
We propose a new method that leverages contextual embeddings for the task of diachronic semantic shift detection by generating time specific word representations from BERT embeddings. The results of our experiments in the domain specific LiverpoolFC corpus suggest that the proposed method has performance comparable to the current state-of-the-art without requiring any time consuming domain adaptation on large corpora. The results on the newly created Brexit news corpus suggest that the method can be successfully used for the detection of a short-term yearly semantic shift. And lastly, the model also shows promising results in a multilingual settings, where the task was to detect differences and similarities between diachronic semantic shifts in different languages.
Dataset for Temporal Analysis of English-French Cognates by Esteban Frossard, Mickael Coustaty, Antoine Doucet, Adam Jatowt, and Simon Hengchen
Languages change over time and, thanks to abundance of digital corpora, their evolutionary analysis using computational techniques has recently gained much research attention. In this paper, we focus on creating a database to investigate the similarity in evolution between different languages. We look in particular into the similarities and differences between the use of corresponding words across time in English and French, two languages from different linguistic families yet with shared syntax and close contact. To analyze this evolution, we select a set of cognates in both languages and study their temporal changes and correlations. We propose a new database for computational approaches of synchronized diachronic investigation of language pairs, and subsequent novel findings stemming from the cognates temporal comparison of the two chosen languages. To the best of our knowledge, the present study is the first in the literature to use computational approaches and large data to make a cross-language temporal analysis.
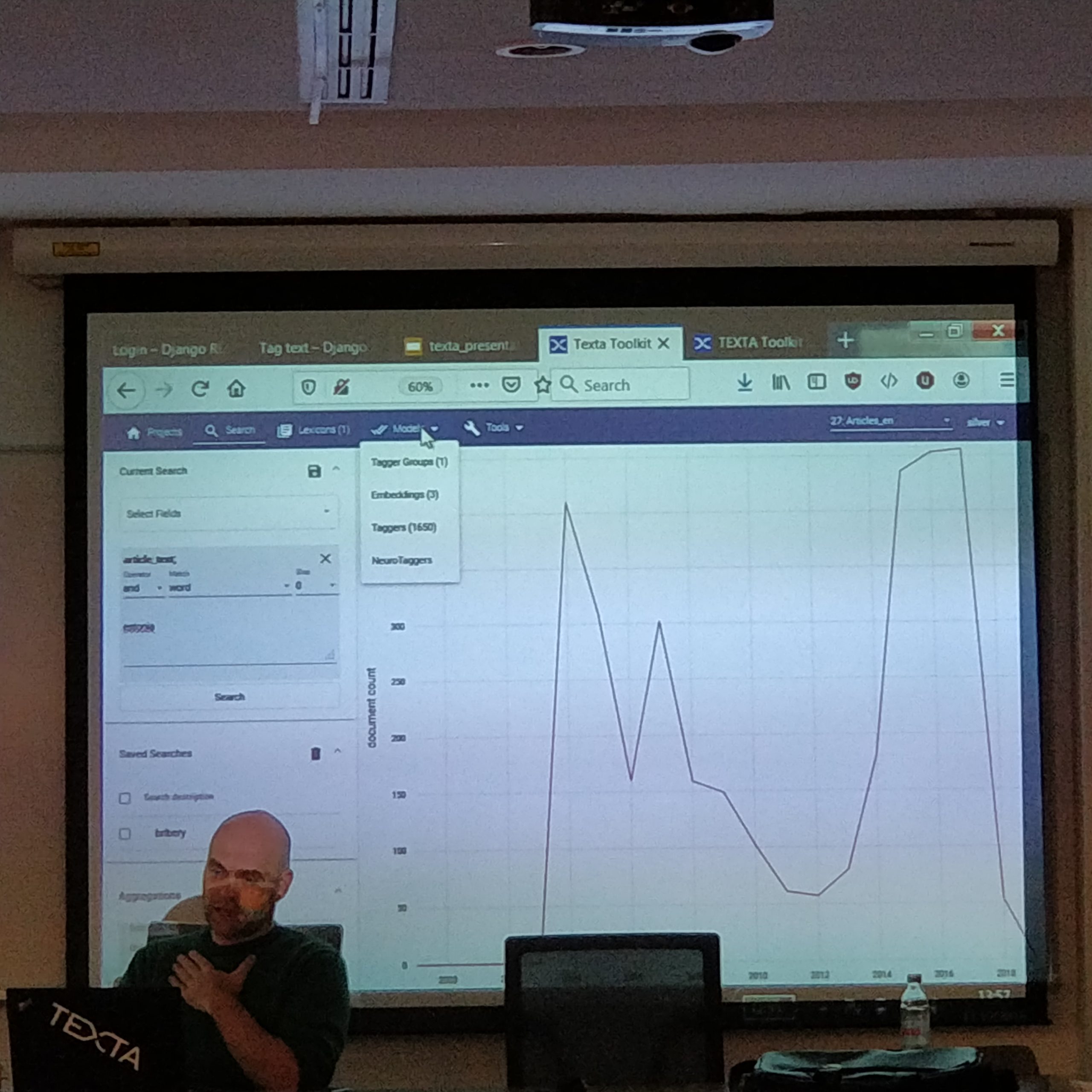
A Dataset for Multi-lingual Epidemiological Event Extraction by Esteban Mutuvi, Antoine Doucet, Gael Lejeune, and Moses Odeo
This paper proposes a corpus for development and evaluation of tools and techniques for identifying emerging infectious disease threats in online news text. The corpus can not only be used for Information Extraction, but also for other Natural Language Processing tasks such as text classification. We make use of articles published on the Program for Monitoring Emerging Diseases (PROMED) platform, which provides current information about outbreaks of infectious disease globally. Among the key pieces of information present in the articles is the Uniform Resource Locator (URL) to the online news sources where the outbreaks were originally reported. We detail the procedure followed to build the dataset, which include leveraging the source URLs to retrieve the news reports and subsequently pre-processing the retrieved documents. We also report on experimental results of event extraction on the dataset using the Data Analysis for Information Extraction in any Language(DANIEL) system. DANIEL is a multilingual news surveillance system that leverages unique attributes associated with news reporting repetition and saliency, to extract events. The system has a wide geographical and language coverage, including low-resource languages. In addition, we compare different classification approaches in terms of their ability to differentiate between epidemic related and non-related news articles that constitute the corpus.
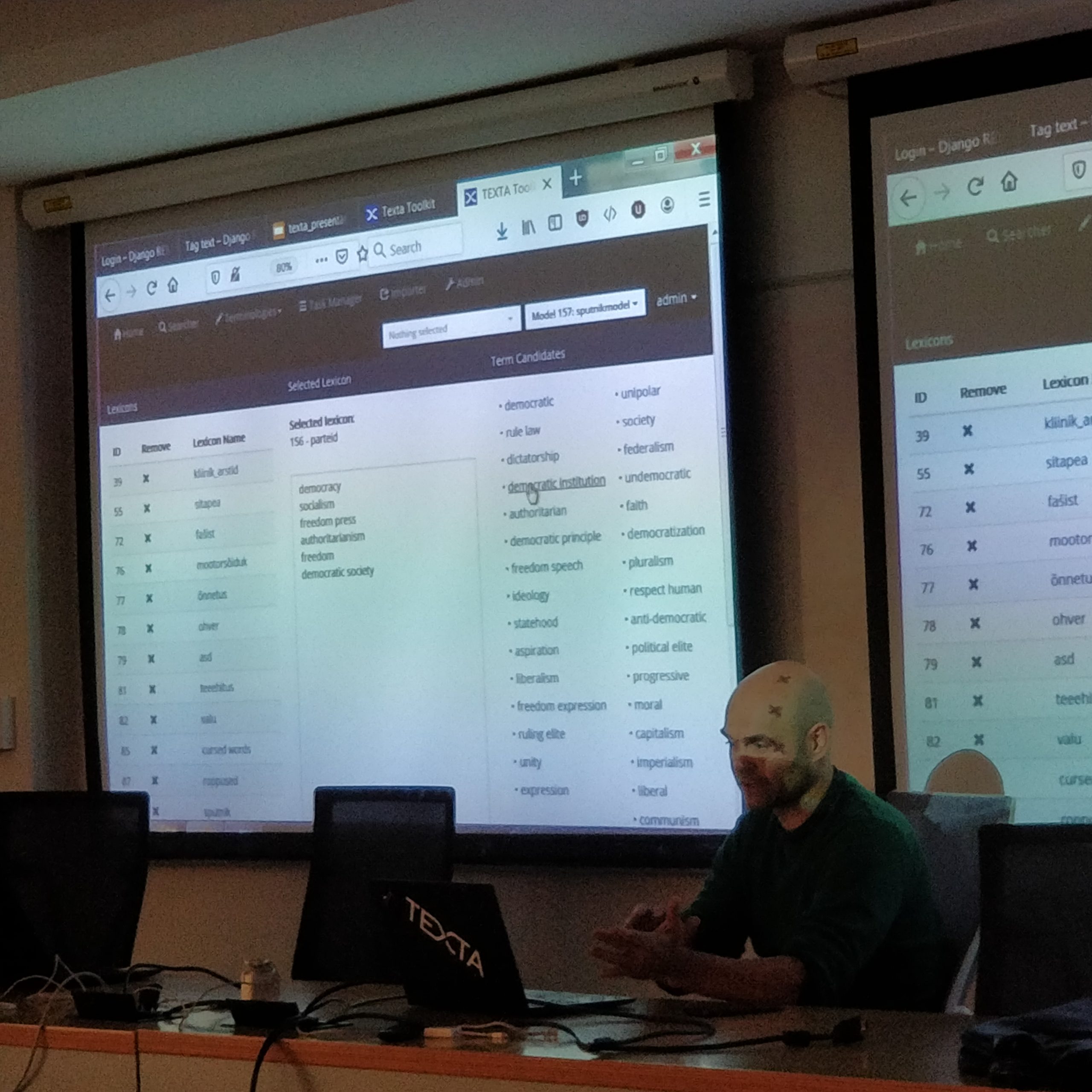
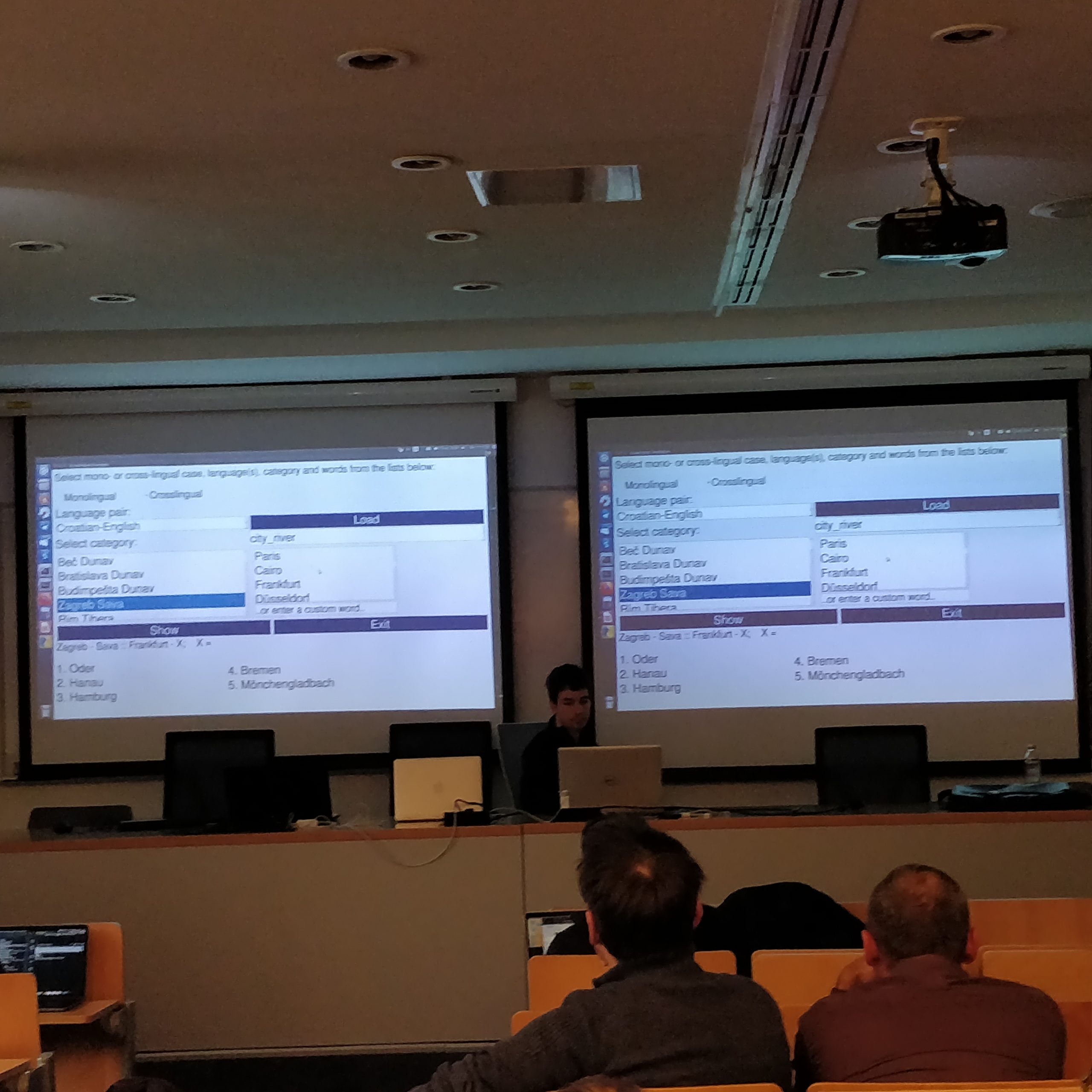
Multilingual Culture-Independent Word Analogy Datasets by Matej Ulčar, Kristiina Vaik, Jessica Lindström, Milda Dailidėnaitė, and Marko Robnik-Šikonja
In text processing, deep neural networks mostly use word embeddings as an input. Embeddings have to ensure that relations between words are reflected through distances in a high-dimensional numeric space. To compare the quality of different text embeddings, typically, we use benchmark datasets. We present a collection of such datasets for the word analogy task in nine languages: Croatian, English, Estonian, Finnish, Latvian, Lithuanian, Russian, Slovenian, and Swedish. We redesigned the original monolingual analogy task to be much more culturally independent and also constructed cross-lingual analogy datasets for the involved languages. We present basic statistics of the created datasets and their initial evaluation using fastText embeddings.
High Quality ELMo Embeddings for Seven Less-Resourced Languages by Matej Ulčar and Marko Robnik-Šikonja
Recent results show that deep neural networks using contextual embeddings significantly outperform non-contextual embeddings on a majority of text classification task. We offer precomputed embeddings from popular contextual ELMo model for seven languages: Croatian, Estonian, Finnish, Latvian, Lithuanian, Slovenian, and Swedish. We demonstrate that the quality of embeddings strongly depends on the size of training set and show that existing publicly available ELMo embeddings for listed languages shall be improved. We train new ELMo embeddings on much larger training sets and show their advantage over baseline non-contextual FastText embeddings. In evaluation, we use two benchmarks, the analogy task and the NER task.
CoSimLex: A Resource for Evaluating Graded Word Similarity in Context by Carlos Santos Armendariz, Matthew Purver, Matej Ulčar, Senja Pollak, Nikola Ljubešič, Marko Robnik-Šikonja, Mark Granroth-Wilding, and Kristiina Vaik
State of the art natural language processing tools are built on context-dependent word embeddings, but no direct method for evaluating these representations currently exists. Standard tasks and datasets for intrinsic evaluation of embeddings are based on judgements of similarity, but ignore context; standard tasks for word sense disambiguation take account of context but do not provide continuous measures of meaning similarity. This paper describes an effort to build a new dataset, CoSimLex, intended to fill this gap. Building on the standard pairwise similarity task of SimLex-999, it provides context-dependent similarity measures; covers not only discrete differences in word sense but more subtle, graded changes in meaning; and covers not only a well-resourced language (English) but a number of less-resourced languages. We define the task and evaluation metrics, outline the dataset collection methodology, and describe the status of the dataset so far.